
Reinforcement Learning ist eine vielversprechende Methode zum Erreichen von Artificial Intelligence. Und zwar insofern, als dass diese Lernmethode eine der vielversprechendsten überhaupt ist, wenn es um die Erlangung der Allgemeinen Künstlichen Intelligenz (Artificial General Intelligence) geht. Reinforcement Learning heißt übersetzt etwa „Bestärkendes Lernen“ oder „Verstärkendes Lernen“. Was es mit dieser Bezeichnung auf sich hat, wie die Methode funktioniert und welche Herausforderungen, Vorteile und welches ungeheure Potential darin steckt, soll dieser Artikel aufzeigen.
Theorie: So funktioniert Reinforcement Learning
Reinforcement Learning gehört – ebenso wie Unsupervised Machine Learning und Supervised Machine Learning – zu den drei algorithmischen Ansätzen in Maschinellem Lernen. Es gibt jedoch einen wesentlichen Unterschied zu den beiden anderen genannten Methoden: Für den Lernvorgang beim Reinforcement Learning sind vorab keine Daten nötig. Eine weitere charakteristische Eigenschaft von Reinforcement Learning: Es handelt sich um eine iterative Methode, die auf dem Prinzip von Trial-and-Error basiert.
Die Lerndaten entstehen beim Reinforcement Learning während des Lernvorgangs selbst. In einer Simulationsumgebung werden im Rahmen von zahlreichen Durchläufen Trainingsdaten generiert und gelabelt. Beim Reinforcement Learning handelt es sich damit um eine der Methoden, bei denen ein Software-Agent selbständig eine Kausalität oder ein Verhalten versteht und die besten Handlungsstrategien in einer gegebenen Situation erlernt.
Das Ziel von Reinforcement Learning: Eine möglichst optimale Policy zu finden
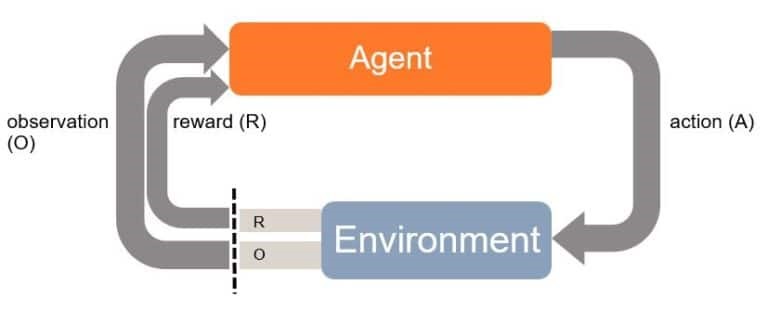
Eine Policy ist vereinfacht gesagt das gelernte Verhalten eines Software-Agents. Die folgende Abbildung zeigt einen schematischen Ablauf eines Lernvorgangs. Eine Policy lässt sich definieren als das gelernte Verhalten mit einer Aktion (Action) auf eine Beobachtung (Observation) in einer Lernumgebung (Enviroment). Ziel ist es, die Policy so zu optimieren, dass die Belohnungen (Rewards) maximiert werden.
Reinforcement Learning in der Praxis: Wie wird Reinforcement Learning eingesetzt?
Von der Theorie in die Praxis: Reinforcement Learning wird schon heute zu ganz konkreten Zwecken eingesetzt. Die aktuell gängigen Use Cases sind hauptsächlich in Bereichen wie der Steuerung von komplexen Systemen (wie beispielsweise bei intelligenten Verkehrsleitsystemen) und intelligenten Lösungen (wie bei der Qualitätsüberwachung) verortet. Reinforcement Learning kann dabei hauptsächlich zum Zweck der „Optimierung“, und „Steuerung“ angewandt werden.
Die Ergebnisse, die hier erzielt werden können, sind beachtlich – die Erwartungen an die Methode müssen jedoch realistisch bewertet werden. Wie bereits erwähnt, zeichnet sich der Lernvorgang dadurch aus, dass die Lösungen näherungsweise erreicht werden. Bevor ein Reinforcement-Learning-Algorithmus funktioniert, sind zahlreiche Trainingsiterationen erforderlich. Das liegt unter anderem daran, dass es verzögerte Belohnungen geben kann und diese erst gefunden werden müssen.
Heute wird Reinforcement Learning beispielsweise zu folgenden Anwendungszwecken eingesetzt:
- Autonomes Fahren
- Steuerung von Robotern
- Optimierung der Supply-Chain oder der Lagerhaltung
- Intelligente Stromnetze
- Fabrikautomatisierung
Zur Erforschung von Reinforcement Learning dienten vor allem Spiele. Denn Spiele bieten eine gute Möglichkeit, um Reinforcement Learning zu erproben und Methoden zu entwickeln. Sie bieten von Haus aus eine Simulationsumgebung, Möglichkeiten zur Steuerung und Beeinflussung der Umgebung, ein komplexes Problem bzw. Spielaufgabe sowie nicht zuletzt meist ein Punktesystem, das als Belohnungssystem dient.
Die Anfänge von DeepMind: Das Lösen von Atari-Spielen
Heute lautet das Unternehmensziel von Googles DeepMind mit Hilfe von Künstlicher Intelligenz, Programme so weiterzuentwickeln, dass sie irgendwann dazu in der Lage sind, beliebig komplexe Probleme ohne menschlichen Einfluss zu lösen. Noch vor ein paar Jahren war ein solches Vorhaben pure Utopie. Einen wesentlichen Beitrag zur Verwirklichung dieser Vision leistet Reinforcement Learning.
Um zu testen, wozu diese Methode in der Lage ist, dienten wie gesagt insbesondere Spiele. Google erkannte die Chancen von Reinforcement Learning bereits sehr früh: Schon im Jahr 2013 investierte Google etwa 365 Millionen Euro in DeepMind. Die Forscher waren damals damit beschäftigt, Atari-Spiele mit der Hilfe von intelligenten Algorithmen zu lösen. Laut Google gelang es DeepMind dank Reinforcement Learning sowohl die Spielregeln als auch Erfolgstaktiken selbstständig zu erlernen.
Reinforcement Learning läutete den Wendepunkt im Bereich der KI-Forschung ein
Die KI von DeepMind erreichte in vielen weiteren Spielen die Fähigkeiten auf dem Niveau von Profispielern und übertraf diese sogar oft. Spätestens zu diesem Zeitpunkt war klar, dass das Potential von Deep Reinforcement Learning enorm war. Das Forschungsprojekt DeepMind markiert den Wendepunkt, seitdem eine gesteigerte Aufmerksamkeit für diese Methode und deren Möglichkeiten zu verzeichnen ist.
Die Herausforderung: Eine der schwierigsten Spiele der Welt – das chinesische Go
Schach ist ein durchaus komplexes Spiel, bei dem es schätzungsweise eine Anzahl von 10120 möglichen Spielen gibt. Diese Zahl wird jedoch vom alten chinesischen Go-Spiel mit Leichtigkeit in den Schatten gestellt. Auf dem 19×19 Felder zählenden Spiel sind mehr als 10170 Spiele möglich. Wie groß die Anzahl an möglichen Spielvarianten ist, wird deutlich, wenn man sich klar macht, dass – nach aktuellen Erkenntnissen – die geschätzte Anzahl der Protonen im beobachtbaren Universum ca. 1080 beträgt.
Aufgrund dieser Komplexität gilt Go als unmöglich für Computerprogramme zu erlernen, geschweige denn zu gewinnen. Neben der Anzahl möglicher Spiele kommt beim Go eine weitere Schwierigkeit hinzu. Nicht jeder mögliche Zug erklärt sich aufgrund einer Logik von Regeln. Immer wieder betonen die Meister des Spiels, dass ihre Intuition das ausschlaggebende Element des Spieles ist.
AlphaGo – ein intelligentes Programm schaffte das Unmögliche. Heute tritt AlphaGo Zero an seine Stelle
Bekannt geworden sind die Leistungen von Googles Künstlicher Intelligenz DeepMind wohl vor allem durch die Arbeit an Alpha Go, der ersten KI, die auf DeepMind basierte. Ihr gelang das bis dato Unmöglich geglaubte: AlphaGo besiegte die weltbesten menschlichen Go-Spieler souverän. AlphaGo Zero, die neueste Fortsetzung von AlphaGo, ist sogar in der Lage, das Spiel von Grund auf selbständig, ohne menschliches Vorwissen zu erlernen.
Das gelingt AlphaGo Zero deswegen, weil es auf Reinforcement Learning basiert. Die KI beginnt dabei völlig zufällig zu spielen. Einzig die Anfangsposition der Spielersteine ist gegeben. Nachdem AlphaGo Zero drei Tage lang trainiert hatte, trat die KI gegen die erste Version von AlphaGo an. Das Ergebnis: Die Zero-Variante konnte ihren Vorgänger 100:0 besiegen.
Reinforcement Learning kann aber zu weit mehr als nur zur Lösung kompliziertester Spiele eingesetzt werden. Die Methode kann vielmehr auch in realen Szenarien Probleme höchst effizient lösen.
Jenseits von Spielen: Google steuert die Klimaanlage mit Reinforcement Learning
Spätestens seit den Erfolgen von AlphaGo ist Google dafür bekannt, an der vordersten Front der KI-Entwicklung zu stehen. Auch Reinforcement Learning spielt dabei eine wichtige Rolle. Diese Methode setzt Google bei der Gleichstromkühlung ein. Zum Hintergrund: Google betreibt riesige Rechenzentren, die nicht nur enorm viel Strom verbrauchen, sondern dabei extrem hohe Temperaturen erzeugen. Zur Kühlung wird dabei ein komplexes System von Klimaanlagen eingesetzt. Mit Reinforcement Learning war es möglich, dieses komplexe, dynamische System zu kontrollieren und zu steuern. Damit war Google in der Lage, durch den Einsatz seines lernfähigen Algorithmus die Energiekosten für die Server-Kühlung um 40 Prozent zu senken.
Reinforcement Learning im Bereich Robotics: Erschließung des wahren Potentials von Industrierobotern
Industrieroboter verrichten hauptsächlich routinemäßige, sich immer gleich wiederholende Aufgaben. Noch fehlt ihnen die Fähigkeit, sich in komplexen Umgebungen zu orientieren und zu verhalten. Um das wahre Potential von Industrieroboter in der Fertigung zu nutzen, ist es jedoch notwendig, dass diese dazu in der Lage sind, auch mit neuen Objekten bzw. neuartigen, sich verändernden Situationen umgehen zu können. Die individualisierte Massenproduktion macht es in Zukunft zunehmend notwendig, dass neuartige Bauteile innerhalb der Serienproduktion erkannt und verwendet werden können.
Damit dies gelingt, müssen Roboter mit einem höheren Grad an Intelligenz ausgestattet. Reinforcement Learning leistet dazu einen entscheidenden Beitrag. Denn mit dieser Methode können intelligente Systeme autonom lernen, mit neuen Szenarien umzugehen. Dazu sind jedoch geeignete Lernumgebungen und ein entsprechendes Maß an Zeit notwendig. In dieser Engineering-Phase eignet sich das lernende System selbständig die Regelungsalgorithmen an, die später dann während der Produktion abgerufen und angewandt werden können, sollte eine entsprechende Situation innerhalb des Fertigungsprozesses auftauchen.
Grundvoraussetzung für den Einsatz von Reinforcement Learning: Wie lautet die konkrete Fragestellung?
Wenn es um den praktischen Einsatz von Reinforcement Learning geht, muss als erstes die Fragestellung richtig verstanden werden. Reinforcement Learning ist nicht für jede Aufgabe gleichermaßen die passende Lösung. Welche Methode zu welchem Use Case passt, lässt sich beispielsweise in einem Use-Case-Workshop herausfinden.
Um herauszubekommen, ob sich Reinforcement Learning für eine bestimmte Fragestellung eignet, sollten Sie überprüfen, ob Ihr Problem einige der folgenden Merkmale aufweist:
- Gibt es die Möglichkeit, das Prinzip von „Trial-and-Error“ anzuwenden?
- Ist Ihre Fragestellung ein Steuerungs- oder Kontrollproblem?
- Gibt es eine komplexe Optimierungs-Aufgabe?
- Lässt sich das komplexe Problem nur bedingt mit traditionellen Engineering-Verfahren lösen?
- Lässt sich die Aufgabe in einer simulierten Umgebung ausführen?
- Ist eine performante Simulationsumgebung vorhanden?
- Kann die Simulationsumgebung beeinflusst werden und deren Status abgefragt werden?
Die Vorteile von Reinforcement Learning
Reinforcement Learning lässt sich idealerweise dann einsetzen, wenn ein bestimmtes Ziel bekannt ist, dessen Lösung aber noch nicht. Beispielsweise: Ein Auto soll selbständig auf dem optimalen Weg von A nach B kommen, ohne einen Unfall zu verursachen. Im Vergleich zu traditionellen Engineering Methoden soll jedoch nicht der Mensch die Lösung vorgeben. Es wird mit möglichst wenigen Vorgaben eine eigene neue Lösung gefunden werden.
Wie bereits weiter oben gesagt, ist einer der großen Vorzüge von Reinforcement Learning ist, dass beim Lernvorgang keine speziellen Trainingsdaten benötigt werden. Im Gegensatz zu Supervised Machine Learning können dadurch neue und unbekannte Lösungen entstehen. Das Erreichen einer neuen optimalen von Menschen unbekannten Lösung ist möglich.
Die Herausforderungen beim Einsatz von Reinforcement Learning
Wer auf Reinforcement Learning setzen will, muss sich darüber bewusst sein, dass damit einige Herausforderungen einhergehen. Allen voran kann der Lernvorgang selbst sehr rechenintensiv sein. Langsame Simulationsumgebungen sind oft der Flaschenhals in Projekten mit Reinforcement Learning.
Daneben ist das Definieren der „Reward-Funktion“ – auch als Reward-Engineering bezeichnet – nicht trivial. Es ist nicht immer von Anfang an ersichtlich, wie die Rewards, also die Belohnungen, zu definieren sind. Darüber hinaus ist das Optimieren der vielen Parameter sehr komplex. Auch die Beschreibung von Beobachtungs- und Aktions-Raum ist manchmal nicht einfach.
Bevor die vergleichsweise aufwändige Methode zum Einsatz kommen kann, stellt sich stets die Frage nach „Exploration vs. Exploitation“. Das heißt in anderen Worten, dass sich die Frage stellt, ob es lohnender ist, neue, unentdeckte und möglicherweise bessere Lösungeswege zu finden oder bestehende Lösungen zu verbessern.
Fazit: Reinforcement Learning hat ein enormes Potential zur Disruption
Reinforcement Learning ist aus mehreren Gründen besonders faszinierend. Zum einen weist die Methode weist sehr enge Beziehungen zu Psychologie, Biologie und den Neurowissenschaften auf. Denn ähnlich wie wir Menschen können dank dieser Lernmethode auch Algorithmen Fähigkeiten entwickeln, die den unseren ähneln. Auch mittels Reinforcement Learning können Computer durch Trial-and-Error selbständig lernen ihre Umgebung zu verstehen und darin eigene Lösungswege zu finden. Mit diesem vergleichsweisen einfachen Prinzip können komplexe Kontroll- und Optimierungsprobleme gelöst werden, die mit traditionellen Methoden nur schwer zu realisieren sind.
Zum anderen fasziniert Reinforcement Learning aufgrund der in die Methode gesteckte Hoffnung, mit ihr eine Allgemeine KI (General Artificial Intelligence) zu erreichen. Es gibt diesbezüglich kaum einen Forschungsbereich, der so vielversprechende Ergebnisse liefert. Dabei ist der Schritt in die Praxis in vielen Fällen schon längst getan. Mit einer geeigneten Simulationsumgebung und einem Belohnungssystem kann Reinforcement Learning zu geradezu beeindruckenden Ergebnissen führen. Aber nicht nur die Erfolge dieser Methode bestätigen, dass Machine Learning im Speziellen und Künstliche Intelligenz im Allgemeinen ein geradezu disruptives Potential haben.

Um einen Kommentar zu hinterlassen müssen sie Autor sein, oder mit Ihrem LinkedIn Account eingeloggt sein.