
Mit der fortschreitenden Digitalisierung wachsen die Datenberge von Unternehmen rasch an. Ein Großteil der wertvollen Informationen liegt jedoch bisher ungenutzt in Form von Texten, Dokumenten und E-Mails vor. Durch zahlreiche Innovationen im Bereich “Natural Language Processing” (NLP) können diese Informationen nun in neuem Maße ausgewertet werden. Dies führt in vielen Industrien zu einem unmittelbaren Informations- und Wettbewerbsvorteil. Ein zentraler Baustein im NLP ist das Erkennen von semantischen Konzepten in Texten – die sogenannte „Named Entity Recognition“.
Unternehmen produzieren kontinuierlich Text-Daten wie E-Mails, Arbeitsprotokolle, Handbücher, Patente u.v.m. Text-Daten kommen aus unterschiedlichen Quellen, werden von verschiedenen Autoren in verschiedenen Sprachen verfasst und sind häufig mit Rechtschreibfehlern behaftet. Um diese Daten in sogenannten Data Lakes zu sichern, werden von Unternehmen große Anstrengungen unternommen. Die Organisation dieser Daten ist oft schwierig und zeitaufwendig, doch automatische Textanalyse macht das möglich.
Für das Finden relevanter Inhalte in komplexen Textsammlungen sind neue Konzepte der Dokumentensuche notwendig. Gängige Verfahren, wie die Suche nach bestimmten Begriffen, also das genaue Abgleichen von Buchstabenfolgen, erweisen sich in Zeiten von Big Data als ineffizient. Das manuelle Prüfen und Klassifizieren von Texten durch Menschen ist wiederum wirtschaftlich kaum finanzierbar. Für Unternehmen ist es dennoch extrem wichtig, sämtliche ihnen verfügbare Daten in ihre Entscheidungen einbeziehen zu können. So würde man im Zuge einer Due Diligence einen mehrere Gigabyte umfassenden Data Room idealerweise vollständig prüfen, anstatt lediglich eine Stichprobe an Dokumenten zu wählen. Auch bei der Erforschung neuer Medikamente könnte man die gesamten 26 Millionen existierenden Publikationen der Medline Datenbank analysieren. Dank moderner Techniken wie Named Entity Recognition können großen Datenmengen analysiert werden.
Named Entity Recognition: automatische und intelligente Erkennung von Konzepten
In der Wissenschaft ist die automatische Erkennung von Konzepten unter dem Begriff Named Entity Recognition (NER) bekannt. Es können generelle Konzepte wie Personen, Orte und Organisationen erkannt werden, aber auch spezifische Begriffe wie Chemikalien oder Kryptowährungen.
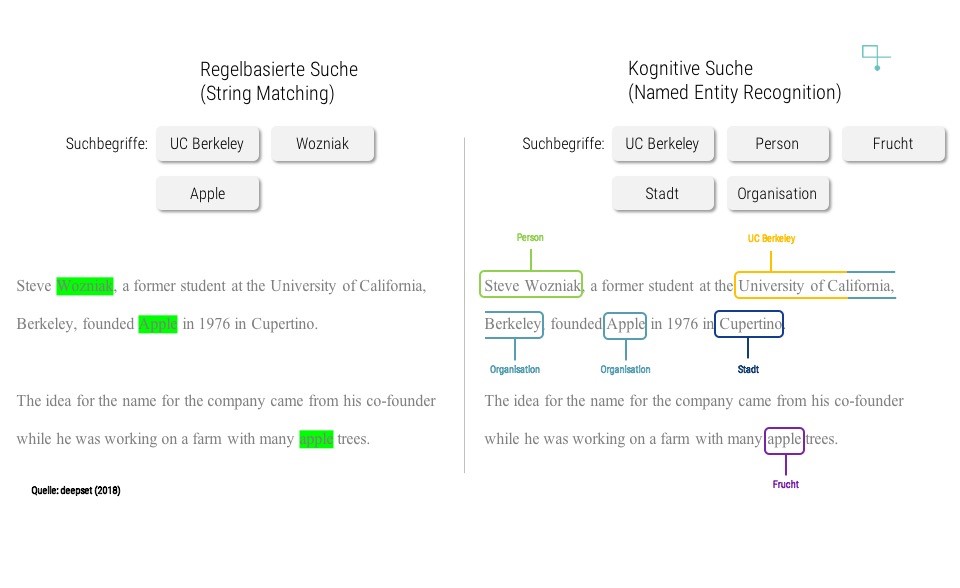
Desweiteren kann ein regelbasiertes System zwischen der Firma oder der Frucht “Apple” nicht unterscheiden.
Die Geschichte der Entwicklung von NER Systemen reicht zurück in die 90er Jahre, hat aber kürzlich, durch Anwendung tiefer neuronaler Netzwerke, enormen Auftrieb bekommen. So wurde die Genauigkeit der Systeme durch zwei grundlegende Verbesserungen erreicht: zum einen können neuronale Netzwerke ganze Sätze oder sogar ganze Dokumente in die Analyse mit einbeziehen – ältere Systeme waren hingegen stets auf wenige Worte beschränkt. Zum anderen ist die mathematische Darstellung einzelner Worte wesentlich fortgeschrittener als früher.
Diese Entwicklung lässt sich gut am Beispiel der Word-Embeddings (deutsch: Wort-Vektoren) erklären. Word-Embeddings sind die erlernte, mathematische Darstellung eines Wortes als Vektor mit semantischem Inhalt. Das bedeutet, zueinander ähnliche Worte haben auch zueinander ähnliche Wort-Vektoren. Zudem kann man auf diesen Wort-Vektoren arithmetische Berechnungen anstellen. Hierzu ein Beispiel:
xPilot – xMann + xFrau = xPilotin
Subtrahiert man “Mann” von “Pilot”, verbleibt im Grunde der Beruf ohne Bezug zu einem Geschlecht. Die Addition von “Frau” verbindet nun den Beruf wieder mit einem Geschlecht und führt zum Ergebnis “Pilotin”. Ein weiteres Beispiel:
xParis – xFrankreich + xDeutschland = xBerlin
Subtrahiert man “Frankreich” von “Paris”, verbleibt die Eigenschaft Hauptstadt. Die Addition von “Deutschland” resultiert dann in der deutschen Hauptstadt.
Diese simple Operation zeigen die Ausdruckskraft der erlernten Word-Embeddings. Nicht nur ähnliche Begriffe können in einem multidimensionalen Raum dargestellt und gefunden werden, sondern auch Konzepte und Relationen können abgebildet und durch grundlegende mathematische Operationen angesprochen werden.
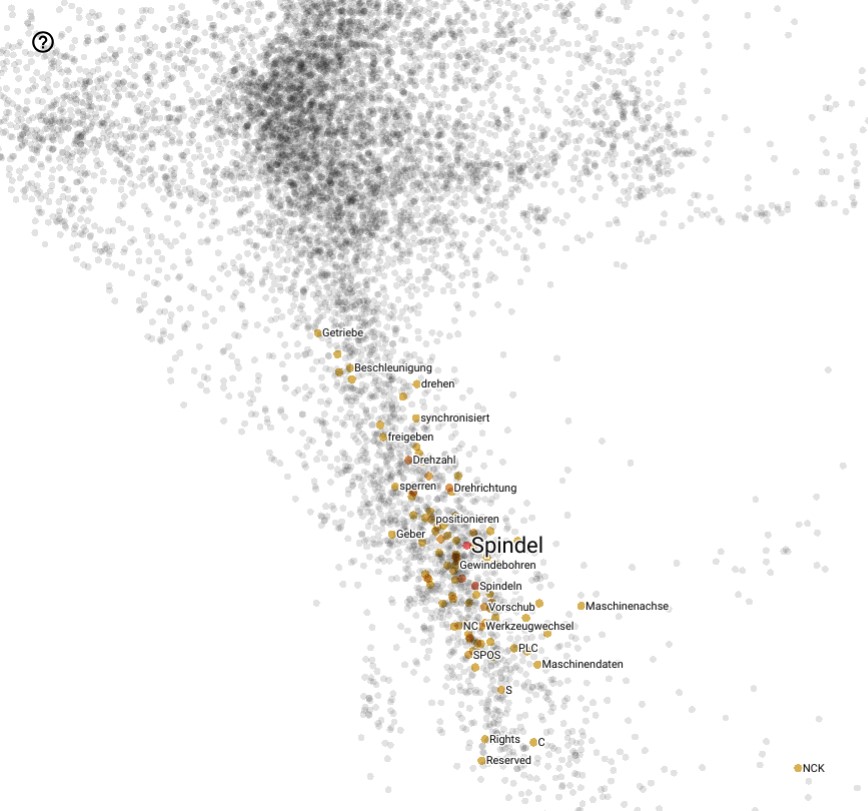
Weit verbreitet ist öffentlich zugängiger Programmcode für das Trainieren der Word-Embeddings. Dieser kann einerseits auf allgemeinen Textkorpora wie dem deutschen Wikipedia, aber auch auf domänen-spezifischen Korpora, wie Gesetzestexten angewandt werden. Gerade letzteres kann von entscheidendem Vorteil bei der Interpretation von Texten für spezifische Anwendungen sein. So benötigt z.B. eine Firma, die sich für Anwendungen im Bereich der Radartechnik interessiert, eine sprachlich sehr feine Unterscheidung bezüglich der eingesetzten Technologien und der Anwendungsgebiete, die mit dem Wort “Radar” in Beziehung stehen.
Modernes NER: Kontext-Verständnis mittels tiefer neuronaler Netzwerke
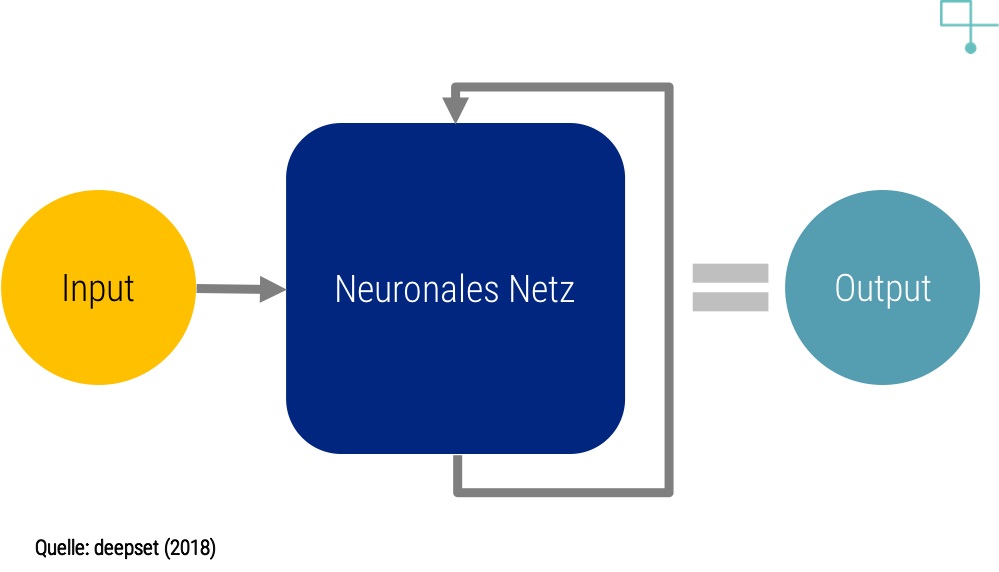
Word-Embeddings legen den Grundstein moderner NER Netzwerke. Worte werden zuerst in maschinen-lesbare Formate verwandelt. Das neuronale Netzwerk muss als nächstes die Sequenz von Wörtern verarbeiten. Nur so kann die Bedeutung eines ganzen Satzes oder Dokuments verstanden werden. Die hier übliche Methode nennt sich Long-Short Term Memory (LSTM). Ein LSTM verarbeitet Daten nicht sequentiell, also nacheinander mit verschiedenen Arbeitsschritten wie an einem Fließband, sondern in einer sich selbst speisenden Verarbeitungs-Schleife (Darstellung rechts). So kann sich das Netzwerk wichtige Aspekte aus vorherigem Input merken und in die Berechnungen zum aktuellen Zeitpunkt einfließen lassen. Wenn also in einem Text die Rede von Essen ist, wird ein auf LSTM basierendes NER-System dem Wort “Apple” nur eine geringe Wahrscheinlichkeit für das Konzept Firma zuweisen.
Für sehr gängige Entitäten wie Namen oder Orte gibt es im Internet bereits trainierte Modelle, die sich mit geringem Aufwand für eigene Zwecke verwenden lassen. So kann man zum Beispiel leicht einen Text von allen Namen bereinigen, um ihn datenschutzkonform an externe Dienstleister zu geben. Für spezielle Anwendungsfälle muss allerdings Vorarbeit geleistet werden. Die größte Hürde ist es ausreichend Beispieltexte mit dazugehörigen Bezeichnungen (sogenannten Labels) zu finden oder zu erstellen. Die Erstellung dieser Beispieldaten kann leicht selbst durchgeführt werden. Möglich machen es Open Source-Tools, die die Markierung von einzelnen Wörtern innerhalb von Texten und die Eingabe der dazugehörenden Bezeichnung erleichtern. Beispiele für solche Tools sind prodi.gy oder das brat annotation tool. Eine andere und besser skalierbare Lösung ist der Einsatz von externen Label-Diensten, die man auch als Crowdsourcing-Dienste bezeichnet.
Durch den leichten Zugang zu performanten Modellen sowie einer Vielzahl von Anwendungsspezifischen Daten können die Herausforderungen der Analyse von großen Text-Daten bewältigt werden. Auch viele kleinere Unternehmen können so nicht nur den Umgang mit Informationen verbessern, sondern vor allem auch den Geschäftserfolg beeinflussen. Sprache als natürlichster Weg des Informationsaustauschs und Text als Dokumentation von Sprache, sind in allen Branchen und Bereichen des alltäglichen Lebens wiederzufinden. Daher wird Named Entity Recognition nicht nur spezifische Probleme lösen können, sondern eröffnet das Potenzial, unseren Zugang zu Informationen in der Zukunft grundlegend zu revolutionieren.

Um einen Kommentar zu hinterlassen müssen sie Autor sein, oder mit Ihrem LinkedIn Account eingeloggt sein.