
Künstliche Intelligenz, konkreter und korrekter Machine Learning bzw. Deep Learning, ist ein Hype, viele große Firmen integrieren derartige Anwendungen in ihre Produkte. Doch kann man als Mittelständler selbst mit Machine Learning eigene Anwendungen erstellen? Hier ein Praxisbericht.
Die NOVENTI HealthCare GmbH ist Europas größtes Abrechnungsunternehmen im Gesundheitswesen mit einem Abrechnungsvolumen von 19 Mrd. Euro jährlich. Mit ca. 1.000 Mitarbeitern werden über 30.000 Apotheken und Sonstige Leistungserbringer wie Physiotherapeuten, Optiker, etc. betreut. Im Geschäftsbereich Apotheken werden pro Monat ca. 14 Mio. Papierrezepte für gesetzlich Versicherte gescannt und mittels einer Texterkennungssoftware in Daten umgewandelt. Die Bilder werden von Hochleistungsscannern als Graustufen und s/w Bilder eingelesen, der farbige Hintergrund und die Feldumrandungen werden mittels eines Farbfilters entfernt. Allerdings gelingt das nicht in allen Fällen zufriedenstellend, es bleiben Artefakte wie Linien oder Feldbeschriftungen übrig. Das verwirrt die eingesetzten Werkzeuge zur Texterkennung, so dass in diesen Fällen nicht immer korrekten Daten gelesen werden können, was manuelle Nacharbeit und damit Kosten verursacht.
Einstieg in Machine Learning
Die NOVENTI HealthCare hat Machine Learning schon einige Zeit als interessante Technologie beobachtet, aber es fehlte jegliche praktische Erfahrung damit. Im Jahr 2017 ergab sich durch eine duale Masterstudentin der Hochschule München im Studiengang Informatik die Möglichkeit, eine Masterarbeit im Bereich Machine Learning zu betreuen. Die Suche nach einem Thema kam schnell zu dem Ergebnis, zwei Arten von Störungen aus den gescannten Bildern zu entfernen: Linien und Feldbeschriftungen, sowie Teile der Unterschrift des Arztes, die sich oft mit wichtigen Daten überschneidet.
Dauerhaften Nutzen aus der Betreuung einer solchen Arbeit hat man aber nur dann, wenn sich interne Entwickler in das Thema einarbeiten und die gewonnenen Erkenntnisse weiterverarbeiten. Die Zusammenarbeit mit der Hochschule München wurde nach Beendigung der Masterarbeit noch vertieft, und stellt eine der Möglichkeiten dar, in das Thema Machine Learning einzusteigen. Die anderen Alternativen sind, sich an spezialisierte Dienstleister zu wenden, die entsprechendes Know-how im Angebot haben, sich selbst mit dem Thema zu beschäftigen oder Mitarbeiter einzustellen, die entsprechendes Wissen mitbringen, die sind allerdings extrem schwer zu bekommen.
Das Wichtigste: die Trainingsdaten
Beim Machine Learning bzw. DeepLearning wird eine Software nicht programmiert, sondern mit Hilfe von Beispielen angelernt. Das, was daraus entsteht, nennt man neuronales Netz, die Daten aus denen es lernt, Trainingsdaten. In diesem Fall sind das Paare aus einem Rezeptbild mit Störung und dem gleichen Bild ohne Störung. Das neuronale Netz trainiert mit diesen Bildpaaren und lernt auf diese Weise, dass es als Ergebnis Bilder mit entfernten Störungen liefern soll. Die Trainingsdaten sind zusammen mit der Struktur des neuronalen Netzes und einigen anderen sog. Hyperparametern das Einzige, das die Logik der entstandenen Anwendung beeinflusst. Daher besteht ein großer Teil des Aufwands darin, ausreichend viele und gute Trainingsdaten zu erzeugen, was in diesem Fall zehntausende Paare aus Bildern mit Störung und zugehörigen Bildern ohne Störung bedeutet hat.
Aufgrund der großen Menge an Rezepten, die von der NOVENTI HealthCare verarbeitet werden, ist die Gewinnung der Trainingsdaten (Bilder mit Störungen) theoretisch einfach. Nachdem man aber nicht zehntausende Bilder per Hand retuschieren möchte, um die Ergebnisdaten zu erzeugen, wurde ein anderer Ansatz gewählt: softwarebasierte Generierung. Für den Anwendungsfall „Entfernung der Unterschrift“ wurden 870 Rezepte ohne Unterschrift mit ca. 5.700 Unterschriften in unterschiedlichen Positionen überlagert. Daraus ergab sich ein Trainingssatz von ca. 12.000 Rezeptbildern. Für den Anwendungsfall „Entfernung von Rahmen und Feldbeschriftungen“ wurden 15.000 Rezepte ohne Störungen mit 45 manuell freigestellter Rahmen überlagert, was dann ca. 180.000 Trainingsbilder ergab.
Anfangsschwierigkeiten
Beim Trainieren von komplexeren neuronalen Netzen kommt man schnell zu der Erkenntnis, dass ohne spezielle Hardware kein ausreichend schnelles Arbeiten möglich ist, da ein Trainingsdurchlauf sonst Wochen dauert. Diese Hardware (meist High-End Grafikkarten) kann man entweder beim Cloud Anbieter seines Vertrauens mieten, wenn der Datenschutzbeauftragte sein OK gibt, oder, wie in diesem Fall, kaufen. Der Grund, warum man sich für einen Kauf entschieden hat, ist: Aufgrund der besonderen Schutzwürdigkeit der Patientendaten dürfen diese das Haus nicht verlassen.
Umsetzung
Die folgenden Absätze gehen auf die verwendeten Ansätze und Technologien ein und sind daher unvermeidlich etwas technischer formuliert. Wen das nicht interessiert, der kann im Absatz „Ergebnisse der Masterarbeit“ weiterlesen.
Es wurden mehrere Ansätze für die Modellierung eines passenden neuronalen Netzes getestet, der Beste für diesen Fall war ein sog. „Denoising Autoencoder“. Die zugrunde liegende Architektur ist eine Ausprägung eines CNN (Convolutional Neural Network), sie ist dabei aufgeteilt in einen sog. Encoder und einen sog. Decoder (siehe Schaubild).
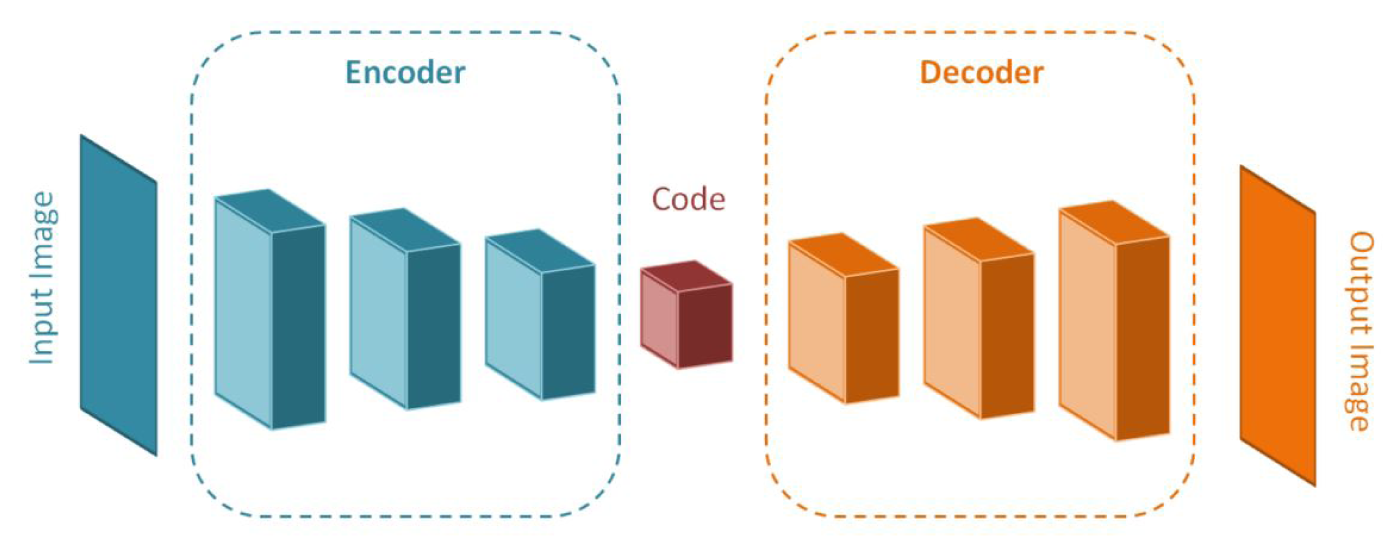
Die Layer im Encoder komprimieren das Eingabebild und extrahieren dessen wichtigste Merkmale. Der Decoder versucht im Anschluss das komprimierte Eingangsbild wieder zu rekonstruieren, diesmal aber ohne die Störungen. Aufgrund der Anzahl der Layer wird diese Art von Machine Learning auch Deep Learning genannt. Die Implementierung des „Denoising Autoencoders“ erfolgte in Python mit dem OpenSource Framework TensorFlow von Google. Neben TensorFlow gib es auch weitere Deep-Learning Frameworks wie Caffee von Facebook, Microsoft Cognitive Toolkit etc. Das Training erfolgte auf einer Graphikkarte und hat jeweils ca. 1 Tag gedauert. Nach jedem Training wurden die Ergebnisse validiert.
Beim Anwendungsfall „Entfernen der Unterschrift“ war der erste Ansatz, das gesamte Rezeptbild als Eingabe für das Training zu verwenden. Da aber von der Unterschrift nur ein kleiner Teil des Bildes betroffen ist, führte das zu keinen guten Ergebnissen, wie die untenstehenden Beispiele verdeutlichen:

Durch die Fokussierung auf den relevanten Bildausschnitt, der die Unterschrift enthält, konnte das Ergebnis jedoch stark optimiert werden:
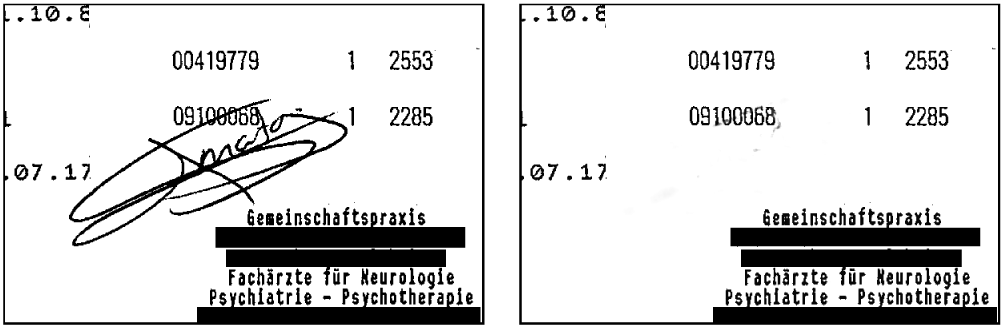
Für den Anwendungsfall „Entfernen der Rahmen“ musste in einem Vorverarbeitungsschritt die Auflösung der Trainingsbilder reduziert werden, da die volle Auflösung der Bilder zu viel Speicher der Grafikkarte verbrauchte. Dadurch, dass sowohl die Eingangsdaten als auch die Ergebnisdaten Bilder sind, ergeben sich Netze mit einer sehr großen Anzahl von Knoten bzw. Parametern, die dann sehr viel Speicher brauchen und auch sehr lange trainieren. In diesem Fall konnte man aber mit der Reduktion der Auflösung leben. Hier ein Beispiel der Entfernung der Rahmen und Feldbeschriftungen:

Ergebnisse der Masterarbeit
Die erstellten neuronalen Netze wurden testweise der Texterkennung vorgeschaltet und es ergab sich eine Verbesserung der Erkennungsqualität um ca. 7% (was für eine bereits extrem optimierte Lösung sehr viel ist). Die Masterarbeit war damit mit einer hervorragenden Leistung abgeschlossen.
Ab in Produktion?
Aufgrund dieser Ergebnisse wurde beschlossen, die Anwendungen produktionsreif zu machen. Dazu haben sich zwei Entwickler der NOVENTI HealthCare in die Implementierung und in die verwendeten Frameworks eingearbeitet und begonnen, die Lösung zu überarbeiten.
Man identifizierte einige Probleme, die in der Generierung der Testdaten begründet liegen. Große neuronale Netze neigen dazu, die Trainingsdaten „auswendig“ zu lernen, anstatt zu generalisieren, wenn die Menge der Trainingsdaten zu gering ist. Das nennt man „Overfitting“. Das äußert sich darin, dass die Ergebnisse mit den Trainingsdaten fast perfekt sind, aber die Anwendung auf unbekannte Daten keine guten Ergebnisse liefert. Die absolute Menge an Trainingsbildern war zwar groß, aber für die Entfernung der Rahmen wurden sie aus nur 45 manuell freigestellten Rahmen erzeugt. Und das war einfach zu wenig. Daher wurde in der Folge für die Generierung der Trainingsdaten noch mehr Rahmen freigestellt, was die Ergebnisse deutlich verbessert hat. Auch wurden sowohl die Struktur der Netze als auch einige Hyperparameter für das Training optimiert.
Ein weiteres Problem war die Performanz der erzeugten Netze. Es wurde bemerkt, dass entgegen erster Hoffnungen die Ausführung der trainierten Netze (Inferenz) auf normalen CPUs viel zu langsam war. Pro Bild dauerte die Optimierung ca. 7-10s. Ursache hierfür war die große Parameteranzahl des verwendeten neuronalen Netzes. Daher wurde neue Hardware mit High-End Grafikkarten für die Produktion besorgt. Mit deren Hilfe reduzierte sich die Ausführung pro Bild auf ca. 100ms, also bis zu Faktor 100 schneller als gegenüber der Berechnung auf einer CPU.
Aktuell sind Massentests mit 1 Mio. Bilder als letzter Schritt geplant, bevor die Anwendung in Produktion geht, was noch für dieses Jahr geplant ist. Während der Arbeit an diesem Projekt ergaben sich weitere Ideen für den Einsatz von Machine Learning, die aktuell untersucht werden.
Fazit
Ein wichtiger Aspekt ist die Zuverlässigkeit der Ergebnisse. Neuronale Netze arbeiten mit statistischen Wahrscheinlichkeiten, programmierte Software (zumindest im Business Bereich) in den meisten Fällen nicht. Man ist also bei herkömmlicher Software exakte, nachvollziehbare Ergebnisse gewohnt. Das Ergebnis eines neuronalen Netzes ist nur mit einer gewissen Wahrscheinlichkeit korrekt. Selbst wenn die sehr hoch ist, heißt das im Umkehrschluss, dass es auch eine kleine Anzahl falscher Ergebnisse liefert. Man findet im Internet immer wieder teils spektakuläre Fehlresultate in den Bilderkennungsdiensten der großen Internetgiganten, die das verdeutlichen. Dieses Problem kann man zwar mit Optimierungen minimieren, aber niemals komplett ausschließen. In dem beschriebenen Fall ist das kein Problem, da die auf den Bildern aufsetzende Texterkennung auch nur mit einer gewissen Wahrscheinlichkeit korrekte Ergebnisse liefert, und die nachfolgenden Systeme damit umgehen können. Wenn Sie planen, Machine Learning einzusetzen und die Ergebnisse korrekt sein müssen, dann kann man nur empfehlen, dass ein Mensch oder ein nachfolgendes System die Ergebnisse nochmals validiert.
Durch die Zusammenarbeit mit der Hochschule München und den Einsatz von eigenen Entwicklern gelang der NOVENTI HealthCare innerhalb eines dreiviertel Jahres ein sehr guter Einstieg in die Verwendung von Machine Learning für selbst entwickelte Software.
Der Aufwand für ein solches Projekt sollte nicht unterschätzt werden. Das gilt für die Einarbeitung in das Thema und die Werkzeuge. Anstelle des Aufwands für die Implementierung von herkömmlicher Software entsteht hier Aufwand für die Gewinnung der Trainingsdaten, für die Evaluierung der Trainingsergebnisse und vor allem für viel Ausprobieren, was für den individuellen Anwendungsfall gut funktioniert und was nicht. Dieser Aufwand ist im Voraus schwer abzuschätzen. Und bei großen und komplexen Netzen muss man auch in eigene Hardware oder entsprechende Cloud-Dienste investieren. Aber der Nutzen überwiegt im beschriebenen Fall den Aufwand bei weitem.

Um einen Kommentar zu hinterlassen müssen sie Autor sein, oder mit Ihrem LinkedIn Account eingeloggt sein.